I tested a range of alternative transliterations of the Voynich text, all based on Glen Claston's v101 but differing from v101 in one or more respects. I numbered these transliterations v101④ through v202. The ④ signifies that in all the transliterations, I treated the v101 glyph pair {4o} as a single glyph, to which I assigned the Unicode symbol ④.
For comparison of the Voynich text with the Arabic language, I used letter frequencies derived from the works of Ibn Kathir (1300-1373).
To prioritize my Voynich transliterations, I started by calculating the statistical correlations between the glyph frequencies and the Arabic letter frequencies. However, with two short descending sequences such as ibn Kathir's Arabic alphabet (which has 43 letters), and the 43 most frequent glyphs in the v101 transliteration (which account for 98.6 percent of the text), it is relatively easy to obtain correlations well in excess of 90 percent. Substantial differences between transliterations, for example combining the {2} group of glyphs, result in quite small changes in the frequency correlations.
I therefore adopted an alternative metric, namely the average frequency difference. Mathematically, this is the average of the absolute differences between the frequency of a precursor letter and the frequency of the equally ranked Voynich glyph. My idea was that the lowest average frequency difference should represent the best fit between a transliteration and the presumed precursor language.
On this metric, I found that the transliteration which I had numbered v171 was the best fit for ibn Kathir's Arabic alphabet. Apart from the treatment of {4o}, the v171 transliteration has the following differences from v101:
Below is a juxtaposition of the frequencies of the top 43 glyphs in the v171 transliteration, and the 43 Arabic letter frequencies. The average frequency difference between v171 and Ibn Kathir's Arabic is 0.64 percent.
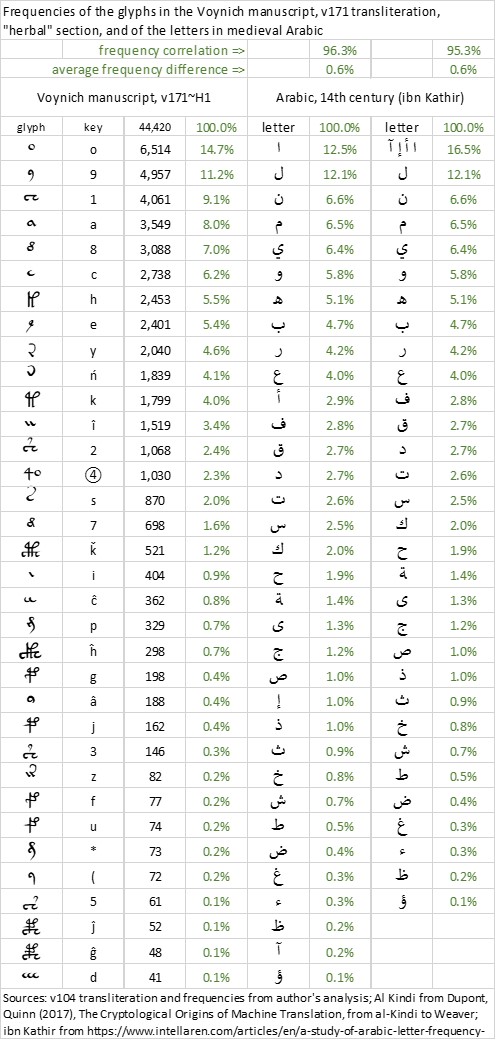
- v171 and Arabic-IK frequencies.jpg (155.73 KiB) Viewed 1488 times
The next step is to explore the potential of these juxtapositions as correspondences or mappings. For example, the most frequent Voynich glyph, {o}, could map to and from the most frequent Arabic letter, ا (alef). Thereby, we could map some of the most common Voynich "words", such as {8am}, {oe} and {1oe}, to text strings in Arabic. We could then search appropriate corpora of the Arabic language to determine whether these strings are real words.
Since Arabic uses an
abjad script, in which the short vowels are not written, the chances are that most of the Voynich "words" up to three glyphs will map to real words in Arabic. However, as I discovered with Persian and with Ottoman Turkish, the mapping may well break down with "words" of four glyphs or longer. Even if we generate real words, those words in sequence may or may not make sense.
Test mappings
Below is a summary of my test mappings of the top five Voynich "words" of one, two, three and four glyphs.
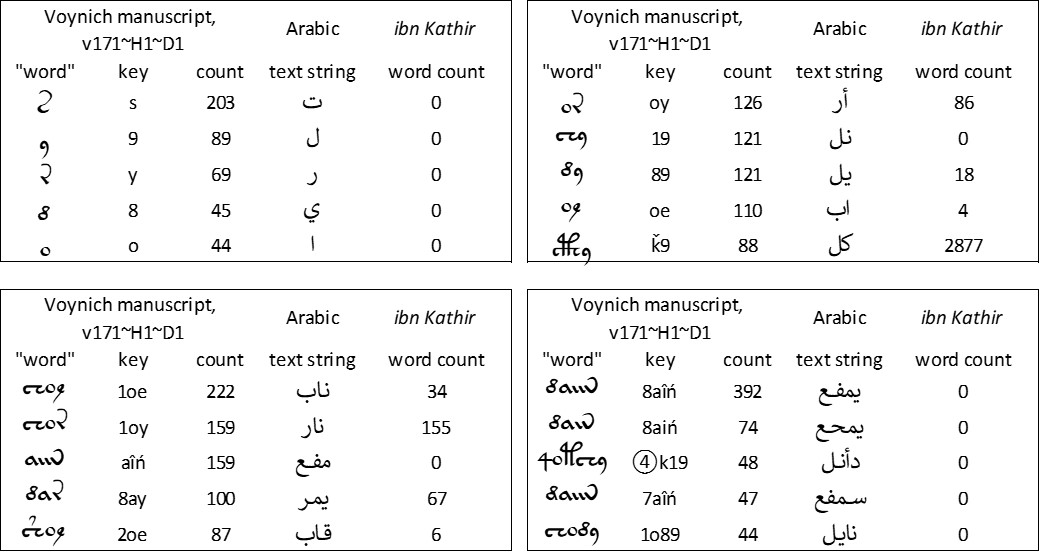
- v171~H1 mappings 1-4 glyphs.jpg (105.23 KiB) Viewed 1469 times
Test mappings of the top ten "words" in the Voynich manuscript, v171 transliteration, "herbal" section, to text strings in medieval Arabic. Author's analysis.
We see here what I am inclined to call the
abjad effect, which I had already observed with Hebrew, Persian and Turkish. Most of the Voynich "words" of two or three glyphs map to real Arabic words. But in an
abjad script, almost any random string of two or three letters will be a real word. At the levels of one glyph and four glyphs, the mapping breaks down.
An alphabetic cipher?
These test mappings do not entirely exclude Arabic as a precursor language of the Voynich manuscript.
As Massimiliano Zattera has demonstrated, in almost every Voynich "word" the glyphs follow a marching order, a kind of alphabetic order. Indeed, Zattera called the sequence a "slot alphabet". We are compelled to imagine that if the Voynich scribes mapped their manuscript from precursor documents, they re-ordered the glyphs in every "word". That would imply that we could take any one of our Arabic text strings, scramble the letters, and still map to the same Voynich "word" from which we started.
To take this idea further would require a good knowledge of Arabic (preferably medieval Arabic), a head for anagrams or Scrabble, and computing power (or patience).
