Further results of the {8am} strategy for mapping the Voynich manuscript: now including mappings of selected "words" to medieval Galician as represented by the first printed edition of
Crónica Troiana, published in 1490, and to medieval English as represented by the full text of the Auchinleck manuscript, published in the 1330s.
https://goodreads.com/author_blog_posts ... -languages
As a corpus of reference for the mapped Galician words, I used
Corpus Xelmirez (
https://ilg.usc.gal/xelmirez/), a corpus of medieval Galician developed by Dr Xavier Varela Barreiro of the Instituto da Lingua Galega in Santiago de Compostela. The website of
Corpus Xelmirez does not indicate how many words are in the corpus; it's probably several million. I recently visited the Instituto da Lingua Galega. I have resumed correspondence with Dr Varela Barreiro.

- {8am} {1oe} {2c9} AR EN GA IT.png (33.49 KiB) Viewed 469 times
Selected mappings of the "words" {8am}, {1oe} and {2c9} to words in selected medieval languages. Author's analysis.
There is a prior manuscript edition of
Crónica Troiana, dated 1393, written by Fernán Martis as a translation from the French
Roman de Troie by Benoît de Sainte-Maure . I have a scanned pdf of the Martis manuscript; it has OCR text but the OCR is not usable. From a comparison of the first pages of the 1393 and 1490 editions, it's clear that the printed edition expanded the earlier abbreviations and concatenations, for example:
- "oconto" in 1393 became "o conto" ("the story") in 1490
- "q̃ndolles" in 1393 became "quando lles" ("when to them") in 1490.
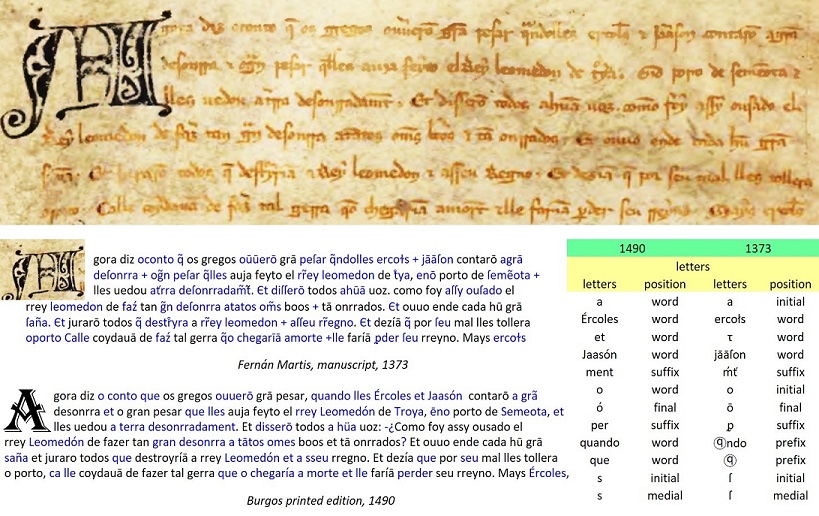
- Cronica Troiana f09r-01-06 1373 & 1490 RevB.jpg (188.34 KiB) Viewed 421 times
Crónica Troiana, first page of text (folio 9r), lines 1-6, from 1393 manuscript and 1490 printed edition.
I have reconstructed a digital text of the Martis 1373 manuscript by identifying some of the common abbreviations and concatenations, and reverse-engineering them from the 1490 printed edition. The resulting digitised text of the 1373 manuscript should permit an alternative calculation of the Galician letter frequencies, and thereby an alternative mapping from Voynich glyphs to Galician letters.
